robots.txt가 뭔가 눈에 자주 띕니다.
이것을 해결하기 위해 robots.txt의 역할을 간단하게 공부를 해봐야 할 것 같습니다.
이 robots.txt는 네이버 검색 등록을 할 때 만나보기는 했습니다.
이 파일은 검색엔진 정보수집을 해도 되는 페이지 인지, 해서는 안 되는 페이지 인지 알려주는 역할을 하는 코드입니다.
데이터베이스 수집을 하는 크롤러가 판단을 하는데 이 크롤링 과부하라는 오류도 많이 보셨을 겁니다.
해야 할게 뭔가 많네요.
그러면 논리적으로 robots.txt에 의해 차단 됐다는 것은 이 파일에 의해 크롤러가 데이터베이스 수집을 하지 않는다라고 보입니다. 그러면 검색엔진에서 불리한 포지션을 가져갈 것 같습니다.
robots.txt의 문법은 어렵지 않은데 공부를 한다면 사실 어렵습니다.
네이버에서 사용한 robots.txt을 한번 볼게요.
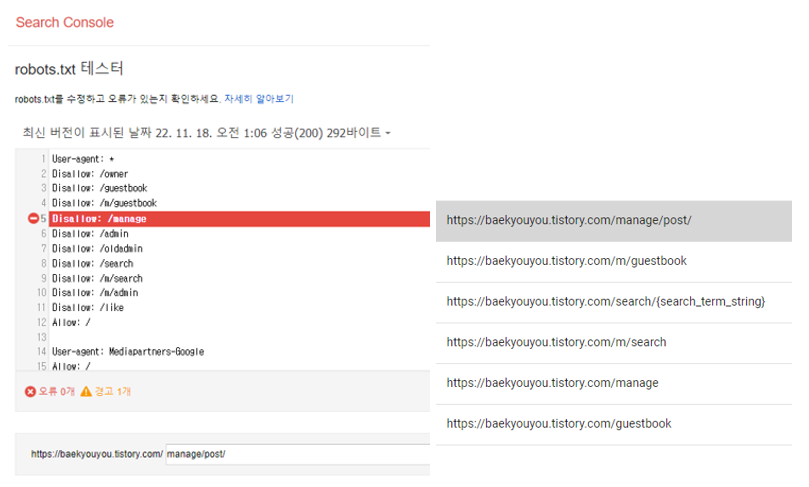
User-agent: * --> 크롤러 지정하는 문법
Allow:/ --> 크롤링을 허용하는 경로
그런데 제가 지금 당장 하고 싶은 것은 제 구글 서치에 당장 이 오류를 치우고 싶은 마음뿐입니다.
그냥 매뉴얼로 바로 가도록 하죠.
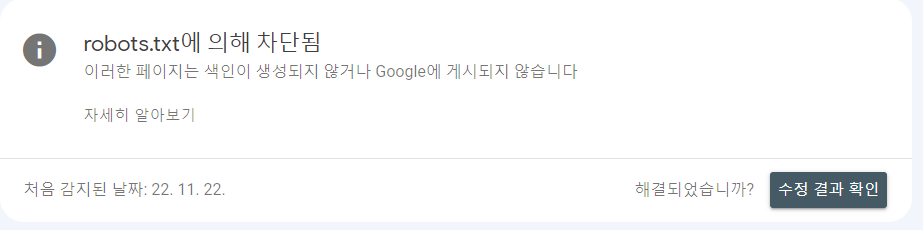
구글 서치 콘솔 - robots.txt에 의해 차단됨
1. 차단 페이지 확인
2. 차단 페이지 확인 후 테스터 접속
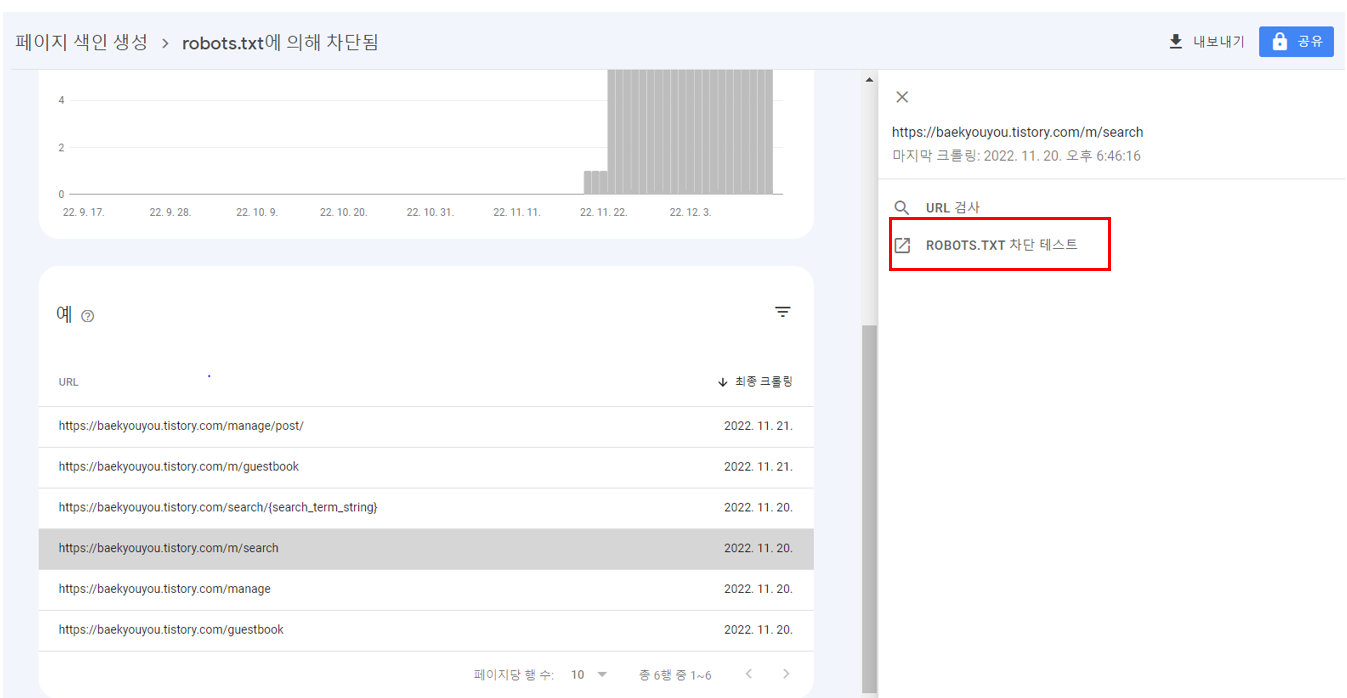
3. 목록을 확인해 봅니다.
robot.txt를 차단하겠다고 하는 페이지를 전부 확인해 보니 뭔가 비슷해 보입니다.
disallow 허용하지 않겠다는 루트가 동일합니다.
manage라는 페이지를 허용하지 않겠다는 뜻인데, 잘 생각해 보니 이거
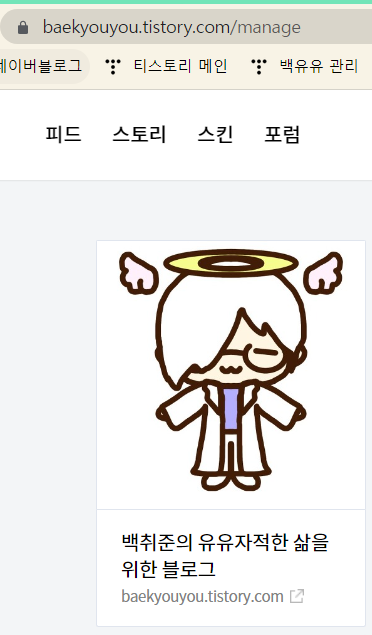
저의 관리 모드 사이트입니다.
그렇다면 당연히 허용되면 안 되겠죠. 저의 개인정보가 검색이 된다는 것과 동일하니까요.
조금 쉽게 이해가 됩니다.
게스트북의 경우도 방명록인데 방명록도 검색과는 거리가 멀겠죠.
이것까지 크롤링할 필요는 없다고 판단됩니다.
그러면 문제가 되는 사이트는 아니라는 결론입니다.
조금 더 수동적으로 확인하시고자 한다면 구글 서치에 나온 robot.txt 차단 페이지의 사이트를 역으로 검색창에 입력을 해보면 됩니다.
그리고 이것이 누구나 검색이 가능한 것인가 아니면 나만 볼 수 있는 것인가를 확인해 보시면 됩니다.
그에 따라 뭔가 오류가 생긴 것이 진짜 페이지 라면 robot.txt 검색 테스트에서 txt 파일을 받아서 다시 적용하면 될 것 같습니다.
테스터 화면에서 1. 제출 클릭 후 2. 다운로드를 합니다.
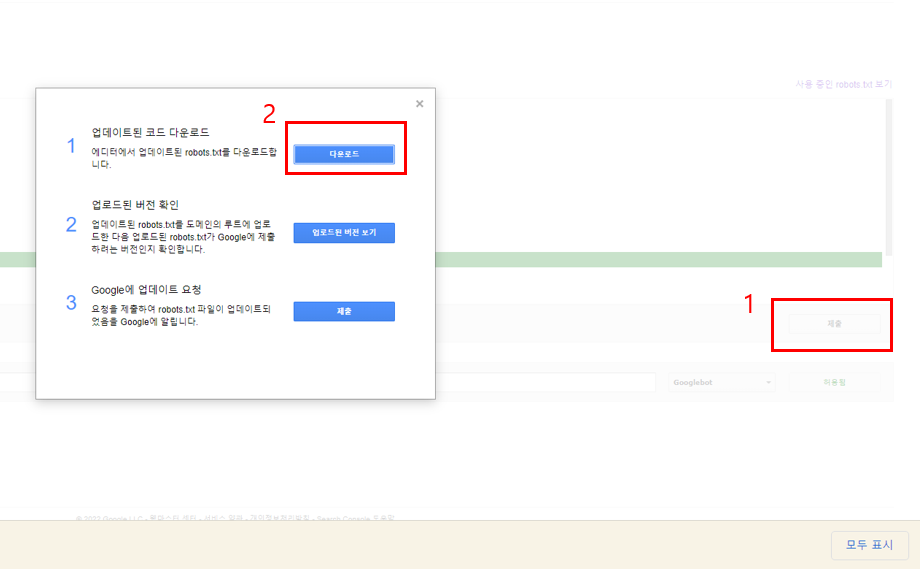
다운로드한 파일을 확인해 봐도 좋을 것 같습니다.
그 후 다운 파일을 업로드해서 해결 가능한 부분도 확인할 수 있을 것 같습니다.
robots.txt 파일 오류를 확인해 보니 개인적인 루트가 포함되어 있는 것을 확인하였습니다.
결국 문제가 되지 않는 부분이지만 오류라고 적용해 둔 것 같습니다.
제 생각에는 알고리즘을 통합해 두었는데 이러한 하나하나 요소까지 따로 설정해두지 않은 것 같습니다.
아무래도 효율의 문제인 것 같기도 하고, 실제로 문제가 된다면 경고를 하면 되니까 통으로 관리하기에는 이쪽이 훨씬 편리해 보입니다.
그렇다면 저기 허용을 하지 않는 방명록은 저의 세팅에 의해 그렇게 된 것이기에 세팅이 바뀌면 없어지게 될 것입니다.
전반적으로 다른 블로그도 확인해 본 결과 robots.txt가 크게 문제 되어 보이지는 않습니다.
문제가 되면 그때 또 연구해 봐야 할 것 같네요.
끝.
'소소한 블로그 운영 방법 > 블로그 각종 오류 해결 방법' 카테고리의 다른 글
| 발견됨 - 현재 색인이 생성되지 않음 해결방법 (1) | 2023.01.07 |
|---|---|
| 크롤링됨 - 현재 색인이 생성되지 않음 해결방법 (0) | 2023.01.02 |
| 사용자가 선택한 표준이 없는 중복 페이지 해결방법 (1) | 2023.01.01 |
| 리디렉션 오류 & 리디렉션이 포함된 페이지 해결방법 (4) | 2022.12.30 |
| 구글 검색엔진, 찾을 수 없음(404) 해결방법 (0) | 2022.12.29 |
| 적절한 표준 태그가 포함된 대체 페이지 해결방법 (0) | 2022.12.28 |
| 구글 서치 URL 검색 등록 방법 (0) | 2022.12.17 |
| robots.txt가 존재하지 않습니다. 해결방법 (0) | 2022.11.24 |

댓글